序列化与反序列化
将不同语言的特有数据结构搞成大家都认的二进制串
将大家都认的二进制串子搞成不同语言的特有数据结构
如果在一大坨微服务构成的庞大业务系统中,各个业务系统之间飞数据的序列化反序列化部分需要技术选型时候,参考标准是什么?
- 性能?序列化和反序列化的速度越快越好,序列化后的数据占用空间越小越好
- 可读性?可读性最好的应该是json咯?这里主要说的是序列化完毕后你肉眼看到的是一坨什么玩意,如果一眼就能看到序列化后那坨玩意是啥样想必会好很多
- 扩展兼容?如果业务频繁改动,添加新字段还要兼容原来业务,对扩展性和兼容性就应该有讲究了
- 健壮性和通用性?主要是通用性吧,要知道如果这个序列化反序列化方案属于某个平台语言专有,那还是很难受的。一个成熟完整的方案一定能够兼顾众多语言众多特性,比如说thrift吧假如TA不支持Java的map或者对php的array支持不好,就有点儿扯了
json
JSON: JavaScript Object Notation(JavaScript 对象表示法)
json: 一般的web项目中,最流行的主要还是 json。因为浏览器对于json 数据支持非常好,有很多内建的函数支持。
|
|
XML
可扩展标记语言(EXtensible Markup Language)
xml: 在 webservice 中应用最为广泛,但是相比于 json,它的数据更加冗余,因为需要成对的闭合标签。json 使用了键值对的方式,不仅压缩了一定的数据空间,同时也具有可读性。
下面实例是 Jani 写给 Tove 的便签,存储为 XML:
|
|
msgpack
It’s like JSON. but fast and small. 简单来讲,它的数据格式与json类似,但是在存储时对数字、多字节字符、数组等都做了很多优化,减少了无用的字符,二进制格式,也保证不用字符化带来额外的存储空间的增加。以下是官网给出的简单示例图:

protobuf
Google Protocol Buffer(简称 Protobuf)是google旗下的一款轻便高效的结构化数据存储格式,平台无关、语言无关、可扩展,可用于通讯协议和数据存储等领域。所以很适合用做数据存储和作为不同应用,不同语言之间相互通信的数据交换格式,只要实现相同的协议格式即同一 proto文件被编译成不同的语言版本,加入到各自的工程中去。这样不同语言就可以解析其他语言通过 protobuf序列化的数据。目前官网提供了 C++,Python,JAVA,GO等语言的支持。google在2008年7月7号将其作为开源项目对外公布。
tips:
- 啥叫平台无关?Linux、mac和Windows都可以用,32位系统,64位系统通吃
- 啥叫语言无关?C++、Java、Python、Golang语言编写的程序都可以用,而且可以相互通信
- 那啥叫可扩展呢?就是这个数据格式可以方便的增删一部分字段啦~
- 最后,啥叫序列化啊?解释得通俗点儿就是把复杂的结构体数据按照一定的规则编码成一个字节切片
使用
1、下载protoc、protoc-gen-go
2、编写proto文件
|
|
3、编译
|
|
其中:
- –proto_path,指定了 .proto 文件导包时的路径,可以有多个,如果忽略则默认当前目录。
- –go_out, 指定了生成的go语言代码文件放入的文件夹
- 允许使用
protoc --go_out=./ *.proto的方式一次性编译多个 .proto 文件 - 编译时,protobuf 编译器会把 .proto 文件编译成 .pd.go 文件
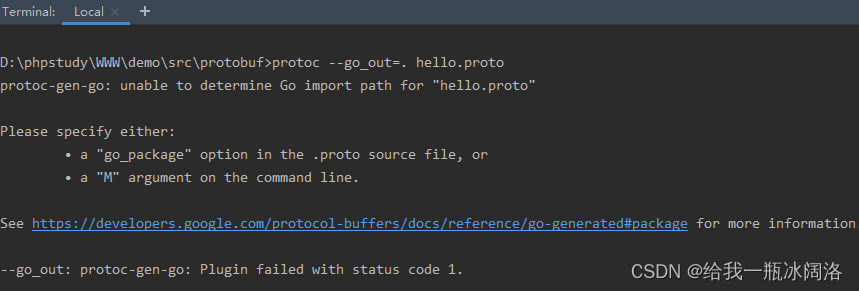
4、编译完成后你就可以使用这个.pd.go 文件了
|
|
mydemo/ ├── protobufDemo ├── pb ├── person.proto ├── person.pb.go ├── main.go
thrift
Apache Thrift软件框架用于可伸缩的跨语言服务开发,它将软件栈和代码生成引擎结合在一起,以构建在C++、Java、Python、PHP、Ruby、Erlang、Perl、Haskell、C#、Cocoa、JavaScript、Node.js、Smalltalk、OCaml和Delphi等语言之间高效、无缝地工作的服务。
Thrift 采用IDL(Interface Definition Language)来定义通用的服务接口,然后通过Thrift提供的编译器,可以将服务接口编译成不同语言编写的代码,通过这个方式来实现跨语言的功能。
- 通过命令调用Thrift提供的编译器将服务接口编译成不同语言编写的代码。
- 这些代码又分为服务端和客户端,将所在不同进程(或服务器)的功能连接起来。